Friday Squid Blogging: Baby Giant Squid Found
First ever examples of a baby giant squid have been found.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
First ever examples of a baby giant squid have been found.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
In 2009, the Australian government released the Protocol for Lightweight Authentication of Identity (PLAID) protocol. It was recently analyzed (original paper is from 2014, but was just updated), and it’s a security disaster. Matt Green wrote a good blog post back in 2014 that explains the problems.
This device is clever: it’s a three-digit combination lock that prevents a USB drive from being read. It’s not going to keep out anyone serious, but is a great solution for the sort of casual security that most people need.
EDITED TO ADD (11/15): Similar products.
Researchers have shown that it is both easy and cheap to surveil connected vehicles.
The second link talks about various anonymization techniques, none of which I am optimistic about.
In August, I wrote about the NSA’s plans to move to quantum-resistant algorithms for its own cryptographic needs.
Cryptographers Neal Koblitz and Alfred Menezes just published a long paper speculating as to the government’s real motives for doing this. They range from some new cryptanalysis of ECC to a political need after the DUAL_EC_PRNG disaster—to the stated reason of quantum computing fears.
Read the whole paper. (Feel free to skip over the math if it gets too hard, but keep going until the end.)
EDITED TO ADD (11/15): A commentary and critique of the paper by Matthew Green.
If the director of the CIA can’t keep his e-mail secure, what hope do the rest of us have—for our e-mail or any of our digital information?
None, and that’s why the companies that we entrust with our digital lives need to be required to secure it for us, and held accountable when they fail. It’s not just a personal or business issue; it’s a matter of public safety.
The details of the story are worth repeating. Someone, reportedly a teenager, hacked into CIA Director John O. Brennan’s AOL account. He says he did so by posing as a Verizon employee to Verizon to get personal information about Brennan’s account, as well as his bank card number and his AOL e-mail address. Then he called AOL and pretended to be Brennan. Armed with the information he got from Verizon, he convinced AOL customer service to reset his password.
The CIA director did nothing wrong. He didn’t choose a lousy password. He didn’t leave a copy of it lying around. He didn’t even send it in e-mail to the wrong person. The security failure, according to this account, was entirely with Verizon and AOL. Yet still Brennan’s e-mail was leaked to the press and posted on WikiLeaks.
This kind of attack is not new. In 2012, the Gmail and Twitter accounts of Wired writer Mat Honan were taken over by a hacker who first persuaded Amazon to give him Honan’s credit card details, then used that information to hack into his Apple ID account, and finally used that information to get into his Gmail account.
For most of us, our primary e-mail account is the “master key” to every one of our other accounts. If we click on a site’s “forgot your password?” link, that site will helpfully e-mail us a special URL that allows us to reset our password. That’s how Honan’s hacker got into his Twitter account, and presumably Brennan’s hacker could have done the same thing to any of Brennan’s accounts.
Internet e-mail providers are trying to beef up their authentication systems. Yahoo recently announced it would do away with passwords, instead sending a one-time authentication code to the user’s smartphone. Google has long had an optional two-step authentication system that involves sending a one-time code to the user via phone call or SMS.
You might think cell phone authentication would thwart these attacks. Even if a hacker persuaded your e-mail provider to change your password, he wouldn’t have your phone and couldn’t obtain the one-time code. But there’s a way to beat this, too. Indie developer Grant Blakeman’s Gmail account was hacked last year, even though he had that extra-secure two-step system turned on. The hackers persuaded his cell phone company to forward his calls to another number, one controlled by the hackers, so they were able to get the necessary one-time code. And from Google, they were able to reset his Instagram password.
Brennan was lucky. He didn’t have anything classified on his AOL account. There were no personal scandals exposed in his email. Yes, his 47-page top-secret clearance form was sensitive, but not embarrassing. Honan was less lucky, and lost irreplaceable photographs of his daughter.
Neither of them should have been put through this. None of us should have to worry about this.
The problem is a system that makes this possible, and companies that don’t care because they don’t suffer the losses. It’s a classic market failure, and government intervention is how we have to fix the problem.
It’s only when the costs of insecurity exceed the costs of doing it right that companies will invest properly in our security. Companies need to be responsible for the personal information they store about us. They need to secure it better, and they need to suffer penalties if they improperly release it. This means regulatory security standards.
The government should not mandate how a company secures our data; that will move the responsibility to the government and stifle innovation. Instead, government should establish minimum standards for results, and let the market figure out how to do it most effectively. It should allow individuals whose information has been exposed sue for damages. This is a model that has worked in all other aspects of public safety, and it needs to be applied here as well.
We have a role to play in this, too. One of the reasons security measures are so easy to bypass is that we as consumers demand they be easy to use, and easy for us to bypass if we lose or forget our passwords. We need to recognize that good security will be less convenient. Again, regulations mandating this will make it more common, and eventually more acceptable.
Information security is complicated, and hard to get right. I’m an expert in the field, and it’s hard for me. It’s hard for the director of the CIA. And it’s hard for you. Security settings on websites are complicated and confusing. Security products are no different. As long as it’s solely the user’s responsibility to get right, and solely the user’s loss if it goes wrong, we’re never going to solve it.
It doesn’t have to be this way. We should demand better and more usable security from the companies we do business with and whose services we use online. But because we don’t have any real visibility into those companies’ security, we should demand our government start regulating the security of these companies as a matter of public safety.
This essay previously appeared on CNN.com.
In Data and Goliath, I talk about the need for transparency, oversight, and accountability as the mechanism to allow surveillance when it is necessary, while preserving our security against excessive surveillance and surveillance abuse.
James Losey has a new paper that discusses the need for transparency in surveillance. His conclusion:
Available transparency reports from ICT companies demonstrate the rise in government requests to obtain user communications data. However, revelations on the surveillance capabilities of the United States, Sweden, the UK, and other countries demonstrate that the available data is insufficient and falls short of supporting rational debate. Companies can contribute by increasing granularity, particularly on the legal processes through which they are required to reveal user data. However, the greatest gaps remain in the information provided directly from governments. Current understanding of the scope of surveillance can be credited to whistleblowers risking prosecution in order to publicize illegitimate government activity. The lack of transparency on government access to communications data and the legal processes used undermines the legitimacy of the practices.
Transparency alone will not eliminate barriers to freedom of expression or harm to privacy resulting from overly broad surveillance. Transparency provides a window into the scope of current practices and additional measures are needed such as oversight and mechanisms for redress in cases of unlawful surveillance. Furthermore, international data collection results in the surveillance of individuals and communities beyond the scope of a national debate. Transparency offers a necessary first step, a foundation on which to examine current practices and contribute to a debate on human security and freedom. Transparency is not the sole responsibility of any one country, and governments, in addition to companies, are well positioned to provide accurate and timely data to support critical debate on policies and laws that result in censorship and surveillance. Supporting an informed debate should be the goal of all democratic nations.
Ravens have been shown to identify and remember cheaters among their unkindness.
Microsoft’s President Brad Smith has a blog post discussing what to do now that the US-EU safe-harbor agreement has collapsed.
He outlines four steps:
First, we need to ensure across the Atlantic that people’s legal rights move with their data. This is a straightforward proposition that would require, for example, that the U.S. government agree that it will only demand access to personal information that is stored in the United States and belongs to an EU national in a manner that conforms with EU law, and vice versa.
Second, this requires a new trans-Atlantic agreement that creates not just a safe harbor, but a new type of connection between two ports. We need to create an expedited process for governmental entities in the U.S. and EU to access personal online information that is moved across the Atlantic and belongs to each other’s citizens by serving lawful requests directly with the appropriate authority in an individual’s home country. The requesting government would seek information only within the limits of its own laws, and its request then would be reviewed promptly by the appropriate government authority in the user’s country of nationality. If the designated authority determines the request is consistent with the privacy protections and other requirements of the citizen’s local law, it would validate and give it legal effect, authorizing disclosure.
[…]
Third, there should be an exception to this approach for citizens who move physically across the Atlantic. For example, the U.S. government should be permitted to turn solely to its own courts under U.S. law to obtain data about EU citizens that move to the United States, and the same is true for a European government when U.S. citizens reside there. This is consistent with longstanding legal principles, as well as the practical reality that public safety issues are most pronounced when an individual is physically present in a jurisdiction.
Finally, it makes sense, except in the most limited circumstances, for governments on both sides of the Atlantic to agree that they will seek to access the content of a legitimate business only by means of service on that business, even when it is stored in the cloud. This would address one of the principal areas of current legal concern for businesses that are relying on cloud services.
We can, and should, argue the details. But this seems like a good place to start for this set of issues.
Some nice options.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
This paper describes what is almost certainly the most sophisticated chip-and-pin credit card fraud to date.
This is impressive:
“An attacker sends an infected packet to a fitness tracker nearby at bluetooth distance then the rest of the attack occurs by itself, without any special need for the attacker being near,” Apvrille says.
“[When] the victim wishes to synchronise his or her fitness data with FitBit servers to update their profile … the fitness tracker responds to the query, but in addition to the standard message, the response is tainted with the infected code.
“From there, it can deliver a specific malicious payload on the laptop, that is, start a backdoor, or have the machine crash [and] can propagate the infection to other trackers (Fitbits).”
That’s attacker to Fitbit to computer.
Both the FBI and local law enforcement are trying to get the genetic data stored at companies like 23andMe.
No surprise, really.
As NYU law professor Erin Murphy told the New Orleans Advocate regarding the Usry case, gathering DNA information is “a series of totally reasonable steps by law enforcement.” If you’re a cop trying to solve a crime, and you have DNA at your disposal, you’re going to want to use it to further your investigation. But the fact that your signing up for 23andMe or Ancestry.com means that you and all of your current and future family members could become genetic criminal suspects is not something most users probably have in mind when trying to find out where their ancestors came from.
A lot has been written about the security vulnerability resulting from outdated and unpatched Android software. The basic problem is that while Google regularly updates the Android software, phone manufacturers don’t regularly push updates out to Android users.
New research tries to quantify the risk:
We are presenting a paper at SPSM next week that shows that, on average over the last four years, 87% of Android devices are vulnerable to attack by malicious apps. This is because manufacturers have not provided regular security updates. Some manufacturers are much better than others however, and our study shows that devices built by LG and Motorola, as well as those devices shipped under the Google Nexus brand are much better than most. Users, corporate buyers and regulators can find further details on manufacturer performance at AndroidVulnerabilities.org.
If you call the proper phone extension, you have complete control over the public address system at a Target store.
“Terrifying” squid photos.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
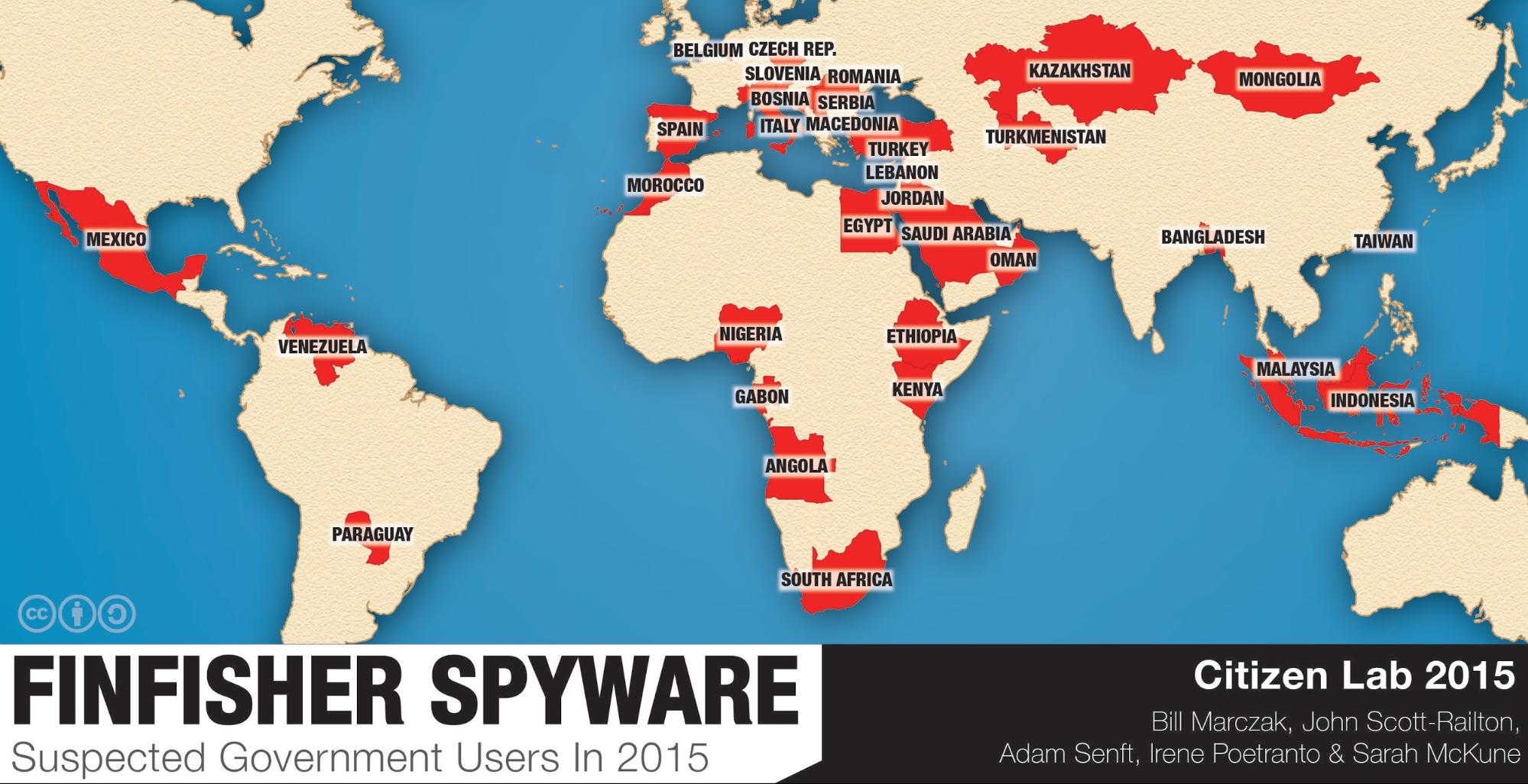
Citizen Lab continues to do excellent work exposing the world’s cyber-weapons arms manufacturers. Its latest report attempts to track users of Gamma International’s FinFisher:
This post describes the results of Internet scanning we recently conducted to identify the users of FinFisher, a sophisticated and user-friendly spyware suite sold exclusively to governments. We devise a method for querying FinFisher’s “anonymizing proxies” to unmask the true location of the spyware’s master servers. Since the master servers are installed on the premises of FinFisher customers, tracing the servers allows us to identify which governments are likely using FinFisher. In some cases, we can trace the servers to specific entities inside a government by correlating our scan results with publicly available sources. Our results indicate 32 countries where at least one government entity is likely using the spyware suite, and we are further able to identify 10 entities by name. Despite the 2014 FinFisher breach, and subsequent disclosure of sensitive customer data, our scanning has detected more servers in more countries than ever before.
Here’s the map of suspected FinFisher users, including some pretty reprehensible governments.
The Internet is abuzz with this blog post and paper, speculating that the NSA is breaking the Diffie-Hellman key-exchange protocol in the wild through massive precomputation.
I wrote about this at length in May when this paper was first made public. (The reason it’s news again is that the paper was just presented at the ACM Computer and Communications Security conference.)
What’s newly being talked about his how this works inside the NSA surveillance architecture. Nicholas Weaver explains:
To decrypt IPsec, a large number of wiretaps monitor for IKE (Internet Key Exchange) handshakes, the protocol that sets up a new IPsec encrypted connection. The handshakes are forwarded to a decryption oracle, a black box system that performs the magic. While this happens, the wiretaps also record all traffic in the associated IPsec connections.
After a period of time, this oracle either returns the private keys or says “i give up”. If the oracle provides the keys, the wiretap decrypts all the stored traffic and continues to decrypt the connection going forward.
[…]
This would also better match the security implications: just the fact that the NSA can decrypt a particular flow is a critical secret. Forwarding a small number of potentially-crackable flows to a central point better matches what is needed to maintain such secrecy.
Thus by performing the decryption in bulk at the wiretaps, complete with hardware acceleration to keep up with the number of encrypted streams, this architecture directly implies that the NSA can break a massive amount of IPsec traffic, a degree of success which implies a cryptanalysis breakthrough.
That last paragraph is Weaver explaining how this attack matches the NSA rhetoric about capabilities in some of their secret documents.
Now that this is out, I’m sure there are a lot of really upset people inside the NSA.
EDITED TO ADD (11/15): How to protect yourself.
The Obama Administration is not pursuing a law that would force computer and communications manufacturers to add backdoors to their products for law enforcement. Sensibly, they concluded that criminals, terrorists, and foreign spies would use that backdoor as well.
Score one for the pro-security side in the Second Crypto War.
It’s certainly not over. The FBI hasn’t given up on an encryption backdoor (or other backdoor access to plaintext) since the early 1990s, and it’s not going to give up now. I expect there will be more pressure on companies, both overt and covert, more insinuations that strong security is somehow responsible for crime and terrorism, and more behind-closed-doors negotiations.
In the 1980s, the Soviet Union bugged the IBM Selectric typewriters in the US Embassy in Moscow. This NSA document discusses how the US discovered the bugs and what we did about it. Codename is GUNMAN.
Is this the world’s first keylogger? Maybe.
Details on the patents issued to the NSA.
Delicious recipe of squid with cabbage, bean sprouts, and noodles.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
EDITED TO ADD (10/9): Posted a day early by mistake….
The show is about security theater. I am a disembodied head on a scooter.
Here’s a teaser. Here’s the full episode (for pay, but cheap).
The scooter idea was a hack when I couldn’t find the time to fly to LA for live filming. The whole thing was a lot of fun.
There’s a new cryptanalysis result against the hash function SHA-1:
Abstract: We present in this article a freestart collision example for SHA-1, i.e., a collision for its internal compression function. This is the first practical break of the full SHA-1, reaching all 80 out of 80 steps, while only 10 days of computation on a 64 GPU cluster were necessary to perform the attack. This work builds on a continuous series of cryptanalytic advancements on SHA-1 since the theoretical collision attack breakthrough in 2005. In particular, we extend the recent freestart collision work on reduced-round SHA-1 from CRYPTO 2015 that leverages the computational power of graphic cards and adapt it to allow the use of boomerang speed-up techniques. We also leverage the cryptanalytic techniques by Stevens from EUROCRYPT 2013 to obtain optimal attack conditions, which required further refinements for this work. Freestart collisions, like the one presented here, do not directly imply a collision for SHA-1.
However, this work is an important milestone towards an actual SHA-1 collision and it further shows how graphics cards can be used very efficiently for these kind of attacks. Based on the state-of-the-art collision attack on SHA-1 by Stevens from EUROCRYPT 2013, we are able to present new projections on the computational/financial cost required by a SHA-1 collision computation. These projections are significantly lower than previously anticipated by the industry, due to the use of the more cost efficient graphics cards compared to regular CPUs. We therefore recommend the industry, in particular Internet browser vendors and Certification Authorities, to retract SHA-1 soon. We hope the industry has learned from the events surrounding the cryptanalytic breaks of MD5 and will retract SHA-1 before example signature forgeries appear in the near future. With our new cost projections in mind, we strongly and urgently recommend against a recent proposal to extend the issuance of SHA-1 certificates by a year in the CAB/forum (the vote closes on October 16 2015 after a discussion period ending on October 9).
Especially note this bit: “Freestart collisions, like the one presented here, do not directly imply a collision for SHA-1. However, this work is an important milestone towards an actual SHA-1 collision and it further shows how graphics cards can be used very efficiently for these kind of attacks.” In other words: don’t panic, but prepare for a future panic.
This is not that unexpected. We’ve long known that SHA-1 is broken, at least theoretically. All the major browsers are planning to stop accepting SHA-1 signatures by 2017. Microsoft is retiring it on that same schedule. What’s news is that our previous estimates may be too conservative.
There’s a saying inside the NSA: “Attacks always get better; they never get worse.” This is obviously true, but it’s worth explaining why. Attacks get better for three reasons. One, Moore’s Law means that computers are always getting faster, which means that any cryptanalytic attack gets faster. Two, we’re forever making tweaks in existing attacks, which make them faster. (Note above: “…due to the use of the more cost efficient graphics cards compared to regular CPUs.”) And three, we regularly invent new cryptanalytic attacks. The first of those is generally predictable, the second is somewhat predictable, and the third is not at all predictable.
Way back in 2004, I wrote: “It’s time for us all to migrate away from SHA-1.” Since then, we have developed an excellent replacement: SHA-3 has been agreed on since 2012, and just became a standard.
This new result is important right now:
Thursday’s research showing SHA1 is weaker than previously thought comes as browser developers and certificate authorities are considering a proposal that would extend the permitted issuance of the SHA1-based HTTPS certificates by 12 months, that is through the end of 2016 rather than no later than January of that year. The proposal argued that some large organizations currently find it hard to move to a more secure hashing algorithm for their digital certificates and need the additional year to make the transition.
As the papers’ authors note, approving this proposal is a bad idea.
More on the paper here.
There’s a lot of information, including the ability to get even more information.
The European Court of Justice ruled that sending personal data to the US violates their right to privacy:
The ruling, by the European Court of Justice, said the so-called safe harbor agreement was flawed because it allowed American government authorities to gain routine access to Europeans’ online information. The court said leaks from Edward J. Snowden, the former contractor for the National Security Agency, made it clear that American intelligence agencies had almost unfettered access to the data, infringing on Europeans’ rights to privacy.
This is a big deal, because it directly affects all the large American Internet companies. If this stands, expect much more pressure on the NSA to stop their indiscriminate spying on everyone.
The judgment. The court’s press release. A good summary of the decision and the issues involved. Intercept article.
EFF blog post. Commentary by Henry Farrell.
Commentary by Max Schrems, who started this proceeding. More commentary by someone involved with the proceedings.
EDITED TO ADD (10/13): Quick explanation.
EDITED TO ADD (10/15): Schrems on the decision and what it means.
Good discussion of the issues. Now we need to think about solutions.
ID checks were a common response to the terrorist attacks of 9/11, but they’ll soon be obsolete. You won’t have to show your ID, because you’ll be identified automatically. A security camera will capture your face, and it’ll be matched with your name and a whole lot of other information besides. Welcome to the world of automatic facial recognition. Those who have access to databases of identified photos will have the power to identify us. Yes, it’ll enable some amazing personalized services; but it’ll also enable whole new levels of surveillance. The underlying technologies are being developed today, and there are currently no rules limiting their use.
Walk into a store, and the salesclerks will know your name. The store’s cameras and computers will have figured out your identity, and looked you up in both their store database and a commercial marketing database they’ve subscribed to. They’ll know your name, salary, interests, what sort of sales pitches you’re most vulnerable to, and how profitable a customer you are. Maybe they’ll have read a profile based on your tweets and know what sort of mood you’re in. Maybe they’ll know your political affiliation or sexual identity, both predictable by your social media activity. And they’re going to engage with you accordingly, perhaps by making sure you’re well taken care of or possibly by trying to make you so uncomfortable that you’ll leave.
Walk by a policeman, and she will know your name, address, criminal record, and with whom you routinely are seen. The potential for discrimination is enormous, especially in low-income communities where people are routinely harassed for things like unpaid parking tickets and other minor violations. And in a country where people are arrested for their political views, the use of this technology quickly turns into a nightmare scenario.
The critical technology here is computer face recognition. Traditionally it has been pretty poor, but it’s slowly improving. A computer is now as good as a person. Already Google’s algorithms can accurately match child and adult photos of the same person, and Facebook has an algorithm that works by recognizing hair style, body shape, and body language - and works even when it can’t see faces. And while we humans are pretty much as good at this as we’re ever going to get, computers will continue to improve. Over the next years, they’ll continue to get more accurate, making better matches using even worse photos.
Matching photos with names also requires a database of identified photos, and we have plenty of those too. Driver’s license databases are a gold mine: all shot face forward, in good focus and even light, with accurate identity information attached to each photo. The enormous photo collections of social media and photo archiving sites are another. They contain photos of us from all sorts of angles and in all sorts of lighting conditions, and we helpfully do the identifying step for the companies by tagging ourselves and our friends. Maybe this data will appear on handheld screens. Maybe it’ll be automatically displayed on computer-enhanced glasses. Imagine salesclerks —or politicians —being able to scan a room and instantly see wealthy customers highlighted in green, or policemen seeing people with criminal records highlighted in red.
Science fiction writers have been exploring this future in both books and movies for decades. Ads followed people from billboard to billboard in the movie Minority Report. In John Scalzi’s recent novel Lock In, characters scan each other like the salesclerks I described above.
This is no longer fiction. High-tech billboards can target ads based on the gender of who’s standing in front of them. In 2011, researchers at Carnegie Mellon pointed a camera at a public area on campus and were able to match live video footage with a public database of tagged photos in real time. Already government and commercial authorities have set up facial recognition systems to identify and monitor people at sporting events, music festivals, and even churches. The Dubai police are working on integrating facial recognition into Google Glass, and more US local police forces are using the technology.
Facebook, Google, Twitter, and other companies with large databases of tagged photos know how valuable their archives are. They see all kinds of services powered by their technologies services they can sell to businesses like the stores you walk into and the governments you might interact with.
Other companies will spring up whose business models depend on capturing our images in public and selling them to whoever has use for them. If you think this is farfetched, consider a related technology that’s already far down that path: license-plate capture.
Today in the US there’s a massive but invisible industry that records the movements of cars around the country. Cameras mounted on cars and tow trucks capture license places along with date/time/location information, and companies use that data to find cars that are scheduled for repossession. One company, Vigilant Solutions, claims to collect 70 million scans in the US every month. The companies that engage in this business routinely share that data with the police, giving the police a steady stream of surveillance information on innocent people that they could not legally collect on their own. And the companies are already looking for other profit streams, selling that surveillance data to anyone else who thinks they have a need for it.
This could easily happen with face recognition. Finding bail jumpers could even be the initial driving force, just as finding cars to repossess was for license plate capture.
Already the FBI has a database of 52 million faces, and describes its integration of facial recognition software with that database as “fully operational.” In 2014, FBI Director James Comey told Congress that the database would not include photos of ordinary citizens, although the FBI’s own documents indicate otherwise. And just last month, we learned that the FBI is looking to buy a system that will collect facial images of anyone an officer stops on the street.
In 2013, Facebook had a quarter of a trillion user photos in its database. There’s currently a class-action lawsuit in Illinois alleging that the company has over a billion “face templates” of people, collected without their knowledge or consent.
Last year, the US Department of Commerce tried to prevail upon industry representatives and privacy organizations to write a voluntary code of conduct for companies using facial recognition technologies. After 16 months of negotiations, all of the consumer-focused privacy organizations pulled out of the process because industry representatives were unable to agree on any limitations on something as basic as nonconsensual facial recognition.
When we talk about surveillance, we tend to concentrate on the problems of data collection: CCTV cameras, tagged photos, purchasing habits, our writings on sites like Facebook and Twitter. We think much less about data analysis. But effective and pervasive surveillance is just as much about analysis. It’s sustained by a combination of cheap and ubiquitous cameras, tagged photo databases, commercial databases of our actions that reveal our habits and personalities, and —most of all —fast and accurate face recognition software.
Don’t expect to have access to this technology for yourself anytime soon. This is not facial recognition for all. It’s just for those who can either demand or pay for access to the required technologies —most importantly, the tagged photo databases. And while we can easily imagine how this might be misused in a totalitarian country, there are dangers in free societies as well. Without meaningful regulation, we’re moving into a world where governments and corporations will be able to identify people both in real time and backwards in time, remotely and in secret, without consent or recourse.
Despite protests from industry, we need to regulate this budding industry. We need limitations on how our images can be collected without our knowledge or consent, and on how they can be used. The technologies aren’t going away, and we can’t uninvent these capabilities. But we can ensure that they’re used ethically and responsibly, and not just as a mechanism to increase police and corporate power over us.
This essay previously appeared on Forbes.com.
The Hawaiian Bobtail Squid deposits bacteria on its eggs to keep them safe.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Former Raytheon CEO Bill Swanson has joined our board of directors.
For those who don’t know, Resilient Systems is my company. I’m the CTO, and we sell an incident-response management platform that…well…helps IR teams to manage incidents. It’s a single hub that allows a team to collect data about an incident, assign and manage tasks, automate actions, integrate intelligence information, and so on. It’s designed to be powerful, flexible, and intuitive—if your HR or legal person needs to get involved, she has to be able to use it without any training. I’m really impressed with how well it works. Incident response is all about people, and the platform makes teams more effective. This is probably the best description of what we do.
We have lots of large- and medium-sized companies as customers. They’re all happy, and we continue to sell this thing at an impressive rate. Our Q3 numbers were fantastic. It’s kind of scary, really.
The news from the Office of Personnel Management hack keeps getting worse. In addition to the personal records of over 20 million US government employees, we’ve now learned that the hackers stole fingerprint files for 5.6 million of them.
This is fundamentally different from the data thefts we regularly read about in the news, and should give us pause before we entrust our biometric data to large networked databases.
There are three basic kinds of data that can be stolen. The first, and most common, is authentication credentials. These are passwords and other information that allows someone else access into our accounts and—usually—our money. An example would be the 56 million credit card numbers hackers stole from Home Depot in 2014, or the 21.5 million Social Security numbers hackers stole in the OPM breach. The motivation is typically financial. The hackers want to steal money from our bank accounts, process fraudulent credit card charges in our name, or open new lines of credit or apply for tax refunds.
It’s a huge illegal business, but we know how to deal with it when it happens. We detect these hacks as quickly as possible, and update our account credentials as soon as we detect an attack. (We also need to stop treating Social Security numbers as if they were secret.)
The second kind of data stolen is personal information. Examples would be the medical data stolen and exposed when Sony was hacked in 2014, or the very personal data from the infidelity website Ashley Madison stolen and published this year. In these instances, there is no real way to recover after a breach. Once the data is public, or in the hands of an adversary, it’s impossible to make it private again.
This is the main consequence of the OPM data breach. Whoever stole the data—we suspect it was the Chinese—got copies the security-clearance paperwork of all those government employees. This documentation includes the answers to some very personal and embarrassing questions, and now opens these employees up to blackmail and other types of coercion.
Fingerprints are another type of data entirely. They’re used to identify people at crime scenes, but increasingly they’re used as an authentication credential. If you have an iPhone, for example, you probably use your fingerprint to unlock your phone. This type of authentication is increasingly common, replacing a password—something you know—with a biometric: something you are. The problem with biometrics is that they can’t be replaced. So while it’s easy to update your password or get a new credit card number, you can’t get a new finger.
And now, for the rest of their lives, 5.6 million US government employees need to remember that someone, somewhere, has their fingerprints. And we really don’t know the future value of this data. If, in twenty years, we routinely use our fingerprints at ATM machines, that fingerprint database will become very profitable to criminals. If fingerprints start being used on our computers to authorize our access to files and data, that database will become very profitable to spies.
Of course, it’s not that simple. Fingerprint readers employ various technologies to prevent being fooled by fake fingers: detecting temperature, pores, a heartbeat, and so on. But this is an arms race between attackers and defenders, and there are many ways to fool fingerprint readers. When Apple introduced its iPhone fingerprint reader, hackers figured out how to fool it within days, and have continued to fool each new generation of phone readers equally quickly.
Not every use of biometrics requires the biometric data to be stored in a central server somewhere. Apple’s system, for example, only stores the data locally: on your phone. That way there’s no central repository to be hacked. And many systems don’t store the biometric data at all, only a mathematical function of the data that can be used for authentication but can’t be used to reconstruct the actual biometric. Unfortunately, OPM stored copies of actual fingerprints.
Ashley Madison has taught us all the dangers of entrusting our intimate secrets to a company’s computers and networks, because once that data is out there’s no getting it back. All biometric data, whether it be fingerprints, retinal scans, voiceprints, or something else, has that same property. We should be skeptical of any attempts to store this data en masse, whether by governments or by corporations. We need our biometrics for authentication, and we can’t afford to lose them to hackers.
This essay previously appeared on Motherboard.
AI theorist Eliezer Yudkowsky coined Moore’s Law of Mad Science: “Every eighteen months, the minimum IQ necessary to destroy the world drops by one point.”
Oh, how I wish I said that.
During the Cold War, the KGB was very adept at identifying undercover CIA officers in foreign countries through what was basically big data analysis. (Yes, this is a needlessly dense and very hard-to-read article. I think it’s worth slogging through, though.)
Sidebar photo of Bruce Schneier by Joe MacInnis.
{kind=link}