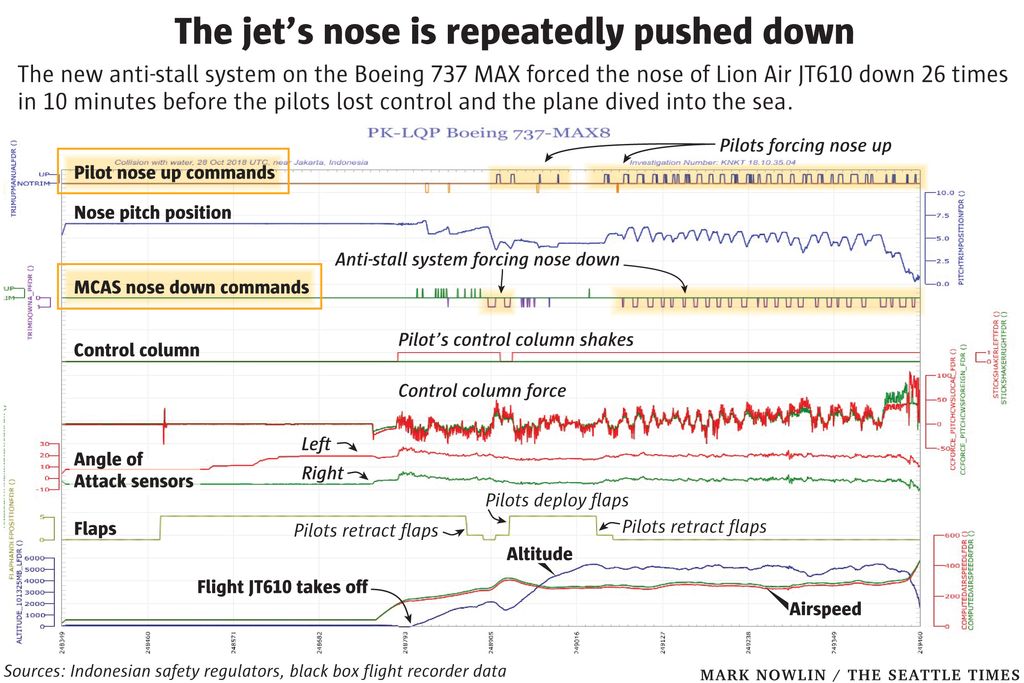
Excellent Analysis of the Boeing 737 Max Software Problems
This is the best analysis of the software causes of the Boeing 737 MAX disasters that I have read.
Technically this is safety and not security; there was no attacker. But the fields are closely related and there are a lot of lessons for IoT security—and the security of complex socio-technical systems in general—in here.
EDITED TO ADD (4/30): A rebuttal of sorts.
EDITED TO ADD (5/13): The comments to this blog post are of particularly high quality, and I recommend them to anyone interested in the topic.
 Subscribe to comments on this entry
Subscribe to comments on this entry {kind=link}
{kind=link}
David Rudling • April 22, 2019 10:00 AM
The author rightly references “Normal Accidents – Living with High-Risk Technologies” by Charles Perrow (1984/1999) which I have oddly just re-read and which is recommended reading for anyone interested in the intersection of security/safety, technology and people.
Also to be recommended is “Safeware – System Safety and Computers” by Nancy Leveson (1995) which I have also just finished reading.
Although neither is recent their continued relevance is because they both present the unchanging fundamentals and do it very well.
Incidentally I read them because I have also recently finished “Click here to kill everybody” by some chap whose name I can’t quite recall but who is a very prominent and distinguished writer in that field !