SHA-1 Collision Found
The first collision in the SHA-1 hash function has been found.
This is not a surprise. We’ve all expected this for over a decade, watching computing power increase. This is why NIST standardized SHA-3 in 2012.
EDITED TO ADD (2/24): Website for the collision. (Yes, this brute-force example has its own website.)
EDITED TO ADD (3/7): This 2012 cost estimate was pretty accurate.
 Subscribe to comments on this entry
Subscribe to comments on this entry 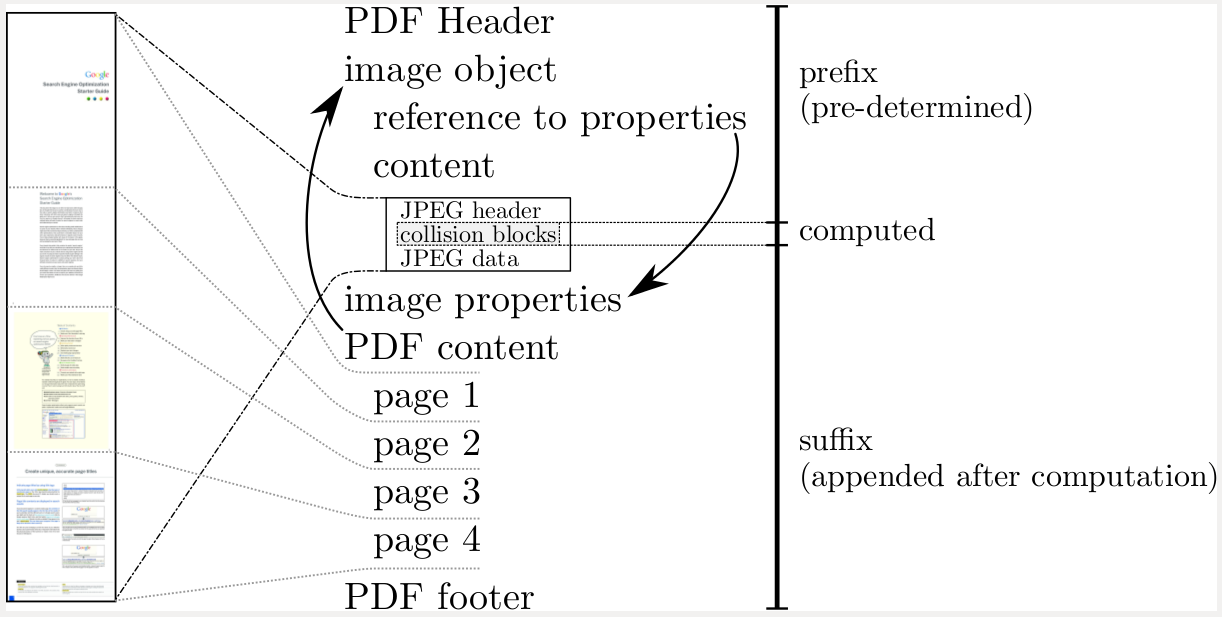{kind=link}
kjzdvhf • February 23, 2017 3:41 PM
Is SHA-3 really necessary, or just an attempt to have a fallback in case SHA-2 is weakened ?